0x00 前言
上一篇笔记记录了学习Python爬虫的简单思路,然后就要对Python爬虫框架进行基本使用了,玩玩更健康
0x01 Scrapy基本介绍
- 基本数据流图解:
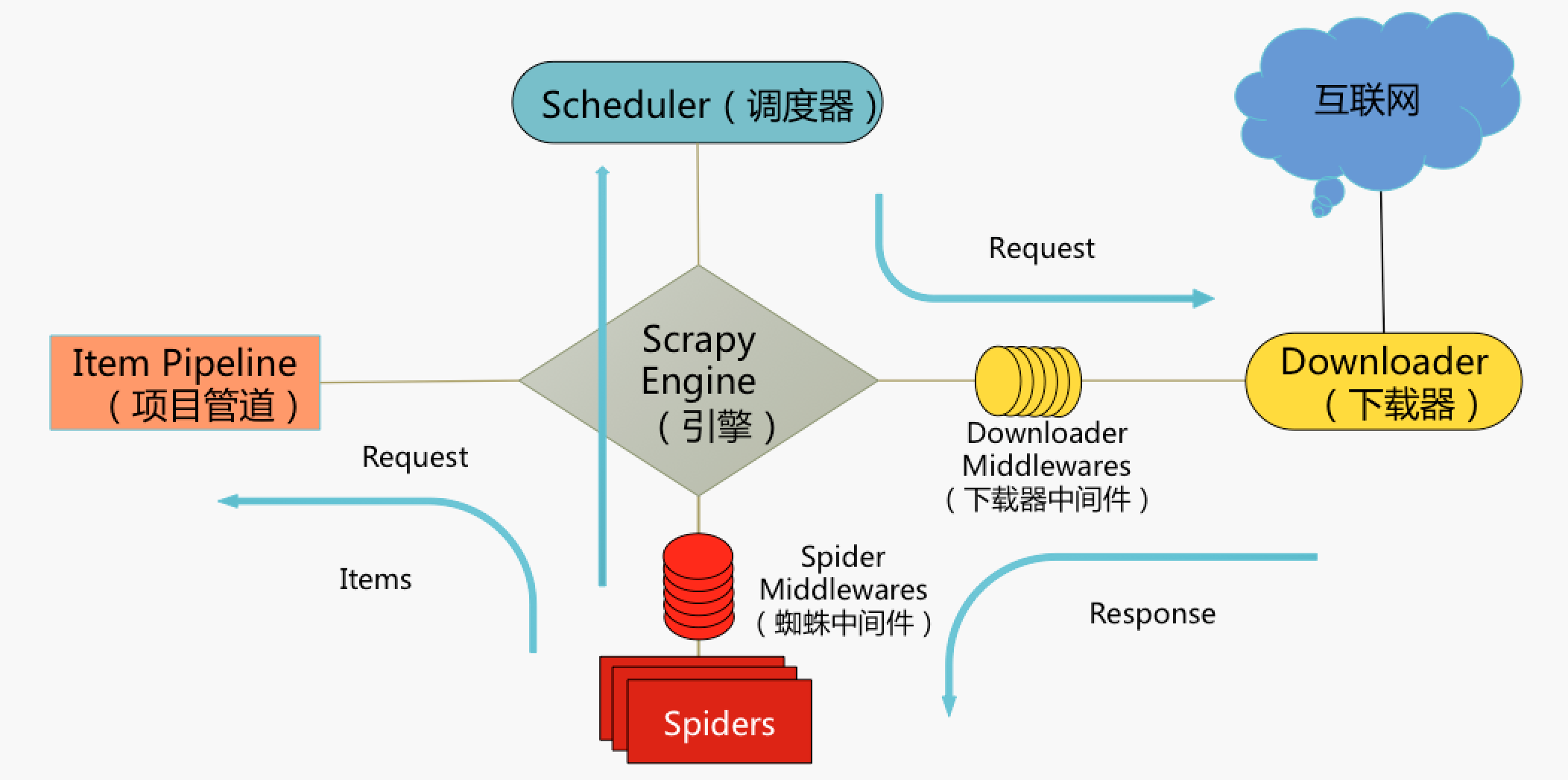
- 基本数据流程:
- Spiders发送第一个URL给引擎
- 引擎从Spider中获取到第一个要爬取的URL后,在调度器(Scheduler)以Request调度
- 调度器把需要爬取的request返回给引擎
- 引擎将request通过下载中间件发给下载器(Downloader)去互联网下载数据
- 一旦数据下载完毕,下载器获取由互联网服务器发回来的Response,并将其通过下载中间件发送给引擎
- 引擎从下载器中接收到Response并通过Spider中间件发送给Spider处理
- Spider处理Response并从中返回匹配到的Item及(跟进的)新的Request给引擎
- 引擎将(Spider返回的)爬取到的Item给Item Pipeline做数据处理或者入库保存,将(Spider返回的)Request给调度器入队列
- (从第三步)重复直到调度器中没有更多的request
- 简单的说:
引擎是大脑,负责在各组件中调度传递信息。我们要编写的几个主要组件就是spider,pipeline和中间件
- 项目结构:
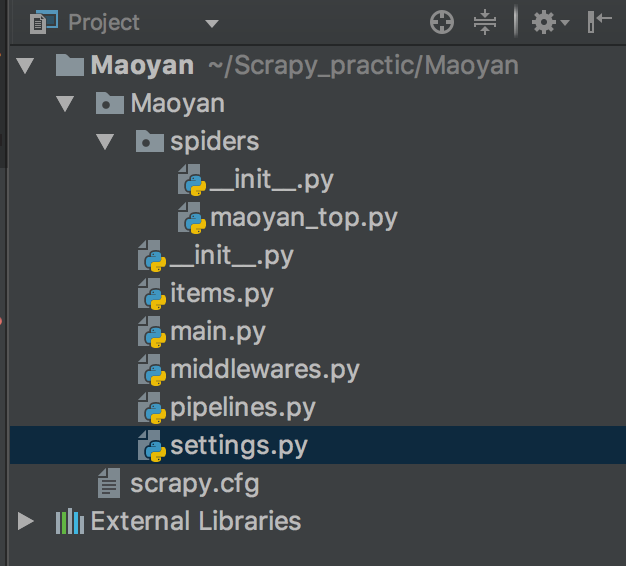
- 编程思路:
还是以猫眼这个简单例子,这次使用了scrapy来实现,首先编写maoyan_top.py,实现爬虫主程序,也就是定义一个爬虫,然后编写items.py定义一个存储数据的数据结构,类似dict,最后编写pipelines.py实现数据存储,这就是最简单的scrapy实现思路
- 首先编写maoyan_top.py,主要就是编写MaoyanTopSpider类,这个类继承scrapy.Spider,定义好基本URL的数据后,就是主力编写parse函数,这个函数就是负责解析数据的。注意这里我yield了item给pipelines.py处理,yield了scrapy.Request给调度器进行翻页爬取
import scrapy |
- 然后编写items.py定义一个存储数据的数据结构给上面的parse函数使用,非常简单我就定义了三个字段,分别为电影的名字,评分和演员
# -*- coding: utf-8 -*- |
- 最后编写pipelines.py进行存储数据,这里要注意parse函数yield出来的item会到达这里处理
class MaoyanPipeline(object): |
- 配置好setting文件激活管道,程序完成
0x02 总结
- 要学scrapy首先要搞清楚这个框架的数据流
- 建议阅读官方文档了解其中的类和方法
- 后面还会继续学习高级一点点的知识,例如url去重,中间件的使用等
refer: